Reading depth
- Part 1 — One Species Splits Into TwoTraining is not shrinking. Inference and training both explode at once — they are complements, not substitutes.Jump to section
- Optical Backbone — The Petabit Era of Distributed TrainingDistributed training beta shows up in optical components as accelerated beta, not linear beta.Jump to section
- Power — Five Sources for the GW CampusPower is now a five-branch market that money alone cannot unlock.Jump to section
- Diversification — The Infrastructure Spread Pattern of Model CompaniesDiversification is the negotiation tool of the pricing-power game — and it is already the standard.Jump to section
- Category Leaders — Stock MappingEach category leader carries a different beta. Memory is almost the only category where Korea is the global number one.Jump to section
- Conclusion — Back to the Big PictureThe big picture is simple. Two infrastructure branches explode together, and category leaders set the beta.Jump to section
Part 1 — One Species Splits Into Two
A single bucket no longer captures what is happening. AI data centers are now two species, and the gap between them keeps widening. One is the training facility — a giant campus in a remote location. The other is the inference facility — a distributed footprint near population centers. They differ in location, in components, in networks, and in power. The same company builds both for the same model. That is now standard practice.
Miss this split and the AI infrastructure investment map blurs. Get it and you can see clearly where the next five years of capital will flow.
Start with the biggest shift. has overtaken training. Two thirds of AI compute went to training in 2023; inference was the third. By early 2026 the ratio had flipped. Inference workloads passed 55% of AI-optimized infrastructure spend, exceeding training cost for the first time. McKinsey projects inference to reach 70~80% of AI compute by 2030. Lenovo's CEO is more direct: "80% inference, 20% training in the future."
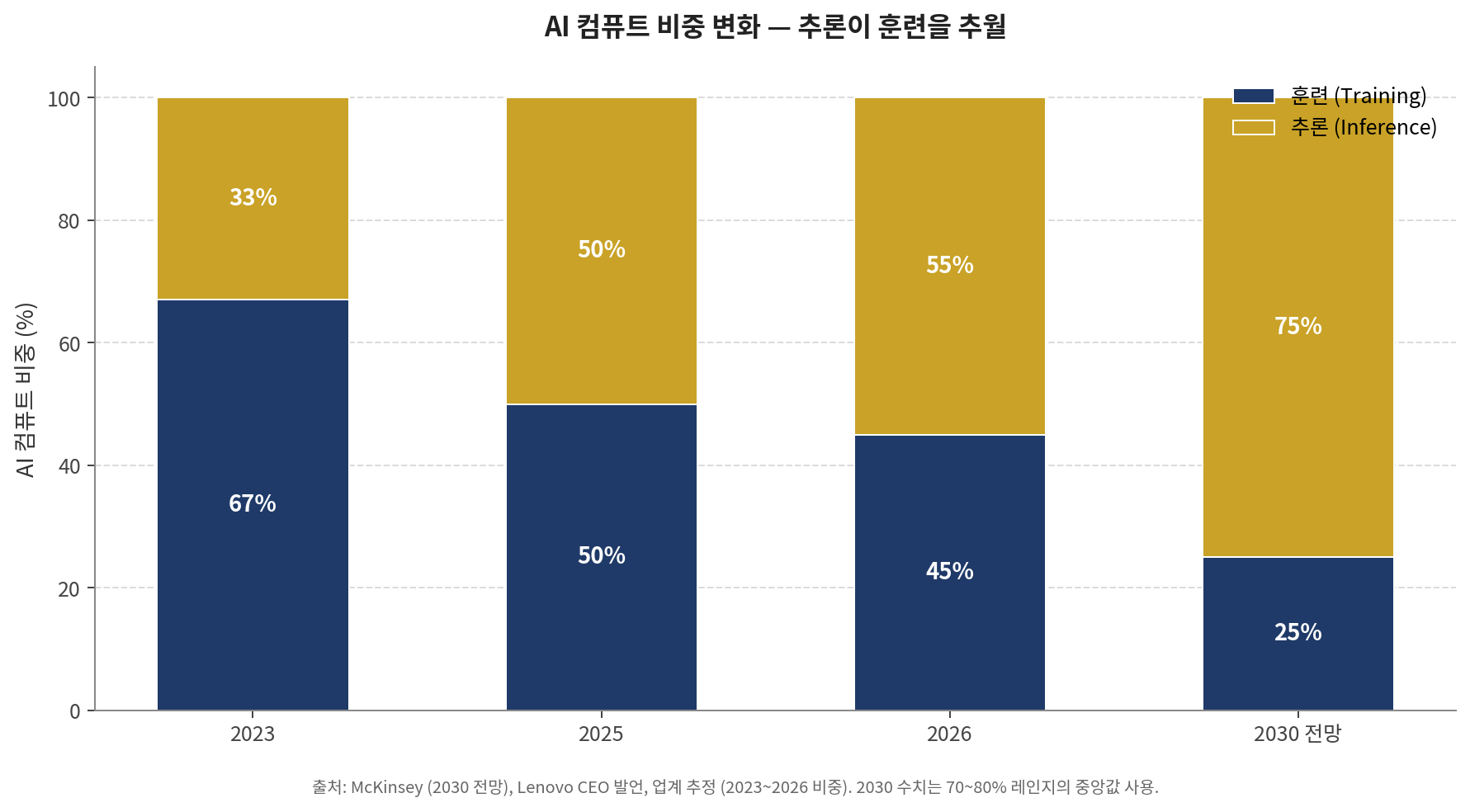
[Chart 1] AI compute share — inference overtakes training
The implication is simple. The old assumption — "training is the main course, inference is a side dish" — is dead. Inference is the main course. Because inference demands different infrastructure, that flip drives the data center split itself.
The first axis of the split is location. Training facilities can sit anywhere. The user is not waiting for an immediate reply. A model trains for days or months and is done. So training campuses move to where electricity is cheap and land is plentiful — Abilene Texas, Ellendale North Dakota, Iowa. Inference is the opposite. A user types a question and expects a response within 50ms. Consumer AI typically targets sub-50ms latency, which forces inference infrastructure to sit near dense populations. So inference facilities cluster near Seoul, Tokyo, New York, London. The same company runs a remote mega-campus on one side and distributed urban-edge facilities on the other.
Different locations mean different power densities. Training facilities are power monsters. NVIDIA's latest GB200 GPU rack consumes 120kW — dozens of office floors' worth. A full campus exceeds 1GW, the output of a single nuclear reactor. At that density, air cannot cool the chips. Liquid cooling becomes mandatory — direct-to-chip or full immersion. Inference is different. Inference GPUs run around 600W per card, 10~40kW per rack. Standard air cooling plus auxiliary cooling is enough. Mixing both inside one facility is wasteful. Liquid cooling on inference nodes is wasted capex; standard cooling on training clusters is insufficient. The split is physically forced, not just commercially preferred.
The deepest difference shows up in the network. The industry already uses two names. Backend fabrics for training. Frontend networks for inference. The backend is where GPUs talk to each other at the speed of light. In training, thousands to tens of thousands of GPUs work the same model in parallel, exchanging results at every step. One slow GPU stalls the rest. So extreme bandwidth gets installed at extreme cost. Inside a server, NVLink links 8 GPUs at 1.8TB/s — tens of thousands of times faster than typical internet links. Between servers, InfiniBand or premium Ethernet fills the gap, with 400G and 800G now standard. Industry consensus says 30~50% of processing time is spent exchanging data over the network, and the economic impact of network performance in AI clusters is enormous. Backend networks reach up to 20% of total cluster cost. Skip them and the GPUs stall.

[Chart 2] Backend fabric vs frontend network — same building, different markets
The frontend is the opposite. User A's question and User B's question are unrelated, so GPUs do not need to synchronize. Training requires 800G+ interconnects; inference runs on standard Ethernet. Alibaba already operates this way — InfiniBand on the training cluster, Ethernet on the inference cluster for cost-effective scaling. This split divides the market itself in two. NVIDIA, via the Mellanox acquisition, has nearly cornered the InfiniBand backend. Arista and Broadcom dominate the Ethernet frontend. An inference market explosion is an Ethernet-camp market explosion.
Inside the inference server, the bill of materials tells another interesting story. It is tempting to call inference "the GPU market," but tear down a server and GPUs are roughly 65% of the cost. Significant, not everything. The remaining 35% drives meaningful collateral revenue. DDR5 system memory contributes about 8%. NVIDIA recommends at least 2x the GPU VRAM in CPU system memory, meaning an 8-GPU inference server holds 1~2TB of DDR5. NVMe SSDs are about 4%, with each server holding 10~30TB for KV-cache backup and model storage. Ethernet NICs are about 5% — eight or nine 400G cards. CPU, motherboard, power, and chassis make up about 18%. Add it all up and non-GPU components are 35%, far from negligible.
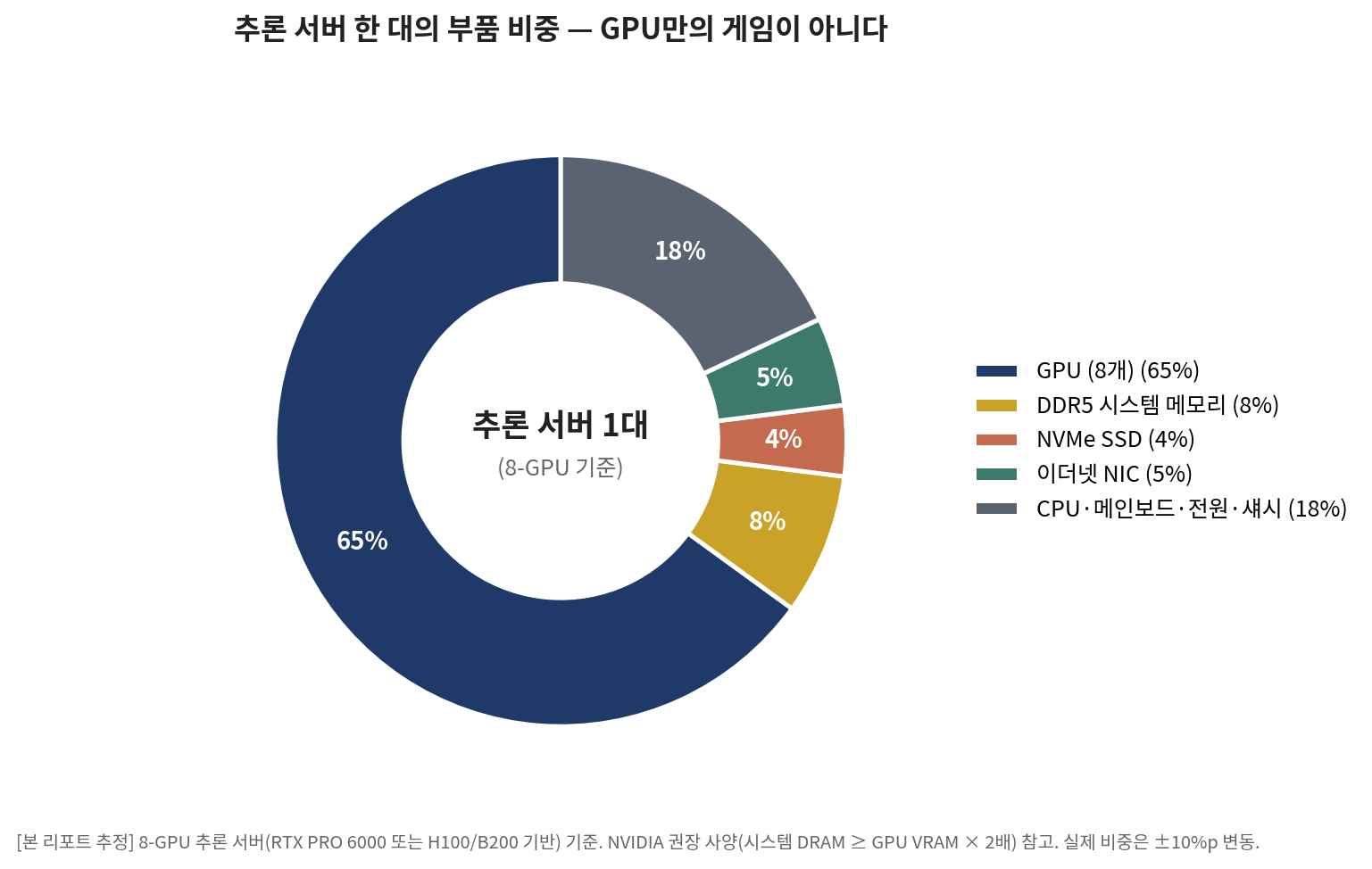
[Chart 3] Inference server bill of materials — not just a GPU game
This structure has a clear implication. The inference market explosion is not a GPU-only game. For every $1 of additional GPU revenue, DDR5, NVMe, and Ethernet NIC pull along $0.40~0.50. The memory three (SK Hynix, Samsung, Micron), the NVMe makers, and the Ethernet switch vendors all benefit directly. Watch only NVIDIA and you miss the whole pull-through.
Now go one level deeper into inference. Many readers miss this part. Inference itself splits into two phases — and . Prefill is the model reading and processing the entire user query at once. Compute load is explosive. GPUs are pegged hard for a short window. NVIDIA H100 or B200 fits well. Decode is the model emitting tokens one at a time, requiring the full model weights to be read from memory each step. Memory bandwidth is the bottleneck, compute is mostly idle, and GPUs stay pegged for a long stretch. Cheaper, memory-fast chips like the RTX PRO 6000 are sufficient.
In the past, the same GPU ran both phases, which created inefficiency. Prefill compute load delayed Decode, and Decode's memory footprint capped the number of concurrent prefill jobs. The fix is splitting the two phases onto different GPUs. Prefill on H100, Decode on RTX PRO 6000. Meta, OpenAI, and Anthropic all run this pattern, and "Disaggregated Inference" is becoming the standard. The implication is plain. Two GPU pools inside an inference facility means this is not an NVIDIA monopoly market. AMD, Cerebras, and custom Broadcom ASICs find clear seats at the table. The technical case for breaking NVIDIA's inference dominance lives here.
A common misconception needs clearing up. "Inference is rising, so training is over." That is wrong. Share and absolute size are different. Even if training falls from 33% to 20% of compute, a market 5x to 10x larger means absolute training spend grows. The numbers back this up. Frontier training power demand grows 2.2~2.9x annually, with single training runs projected to reach 4~16GW by 2030. The largest current single facility — Anthropic-AWS's New Carlisle at 1.1GW and $35B — gets nearly 8x bigger in Microsoft Fairwater Wisconsin by September 2027.
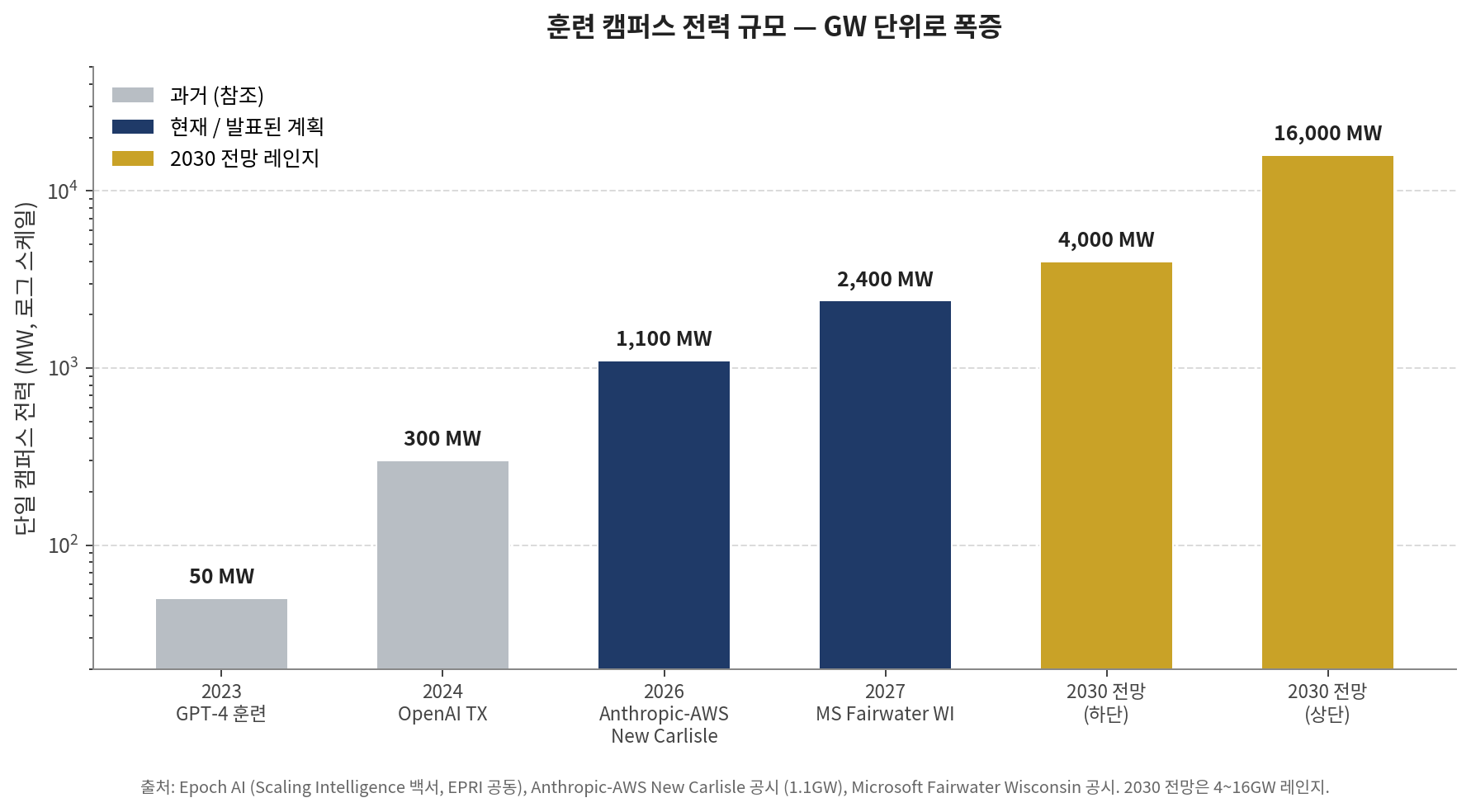
[Chart 4] Training campus power footprint — exploding into the GW range
Training is not shrinking. It is exploding into GW units. The shape of training itself is also expanding. Pretraining alone may slow, but post-training, reinforcement learning, and synthetic data generation all stack on top. Reasoning models like o1 and R1 burn as much compute on RL as pretraining did. All of that runs in backend facilities. Training and inference markets explode at the same time. They are not zero-sum. They are complements. The more revenue inference earns, the clearer the ROI on better models, which feeds even larger training cluster investment.
That is the Part 1 diagnosis. AI data centers split in two, and both halves are exploding at the same time. To see the full picture you need to follow each branch separately. The training branch raises three questions. Who builds the GW-scale campuses? Where does the power come from? Who lays the optical backbone between sites? The inference branch raises three more. Where does it distribute? Who supplies the standard components? Who occupies the new cloud category? Part 2 and Part 3 answer these.
Training is not shrinking. Inference and training both explode at once — they are complements, not substitutes.