해해랑달·Founder Analyst2026년 5월 10일읽기 19분AI인프라, 데이터센터분기, 훈련추론분리, 광백본, 전력5갈래, BloomEnergy, GEVernova, Broadcom, AMD, Marvell, Coherent, Lumentum, Ciena, 메모리3사, CoreWeave, 다변화패턴
읽기 깊이
- Part 1 — 한 종류였던 것이 둘로 쪼개진다훈련은 줄지 않는다. 추론과 훈련은 둘 다 동시에 폭증하는 보완 관계다.본문으로 이동
- 광 백본 — 분산 훈련이 만드는 페타비트 시대분산 훈련 베타는 광부품에서 가속 베타로 나타난다.본문으로 이동
- 전력 — GW급 캠퍼스의 5대 공급원전력은 이제 돈으로도 안 풀리는 5갈래 시장이 됐다.본문으로 이동
- 다변화 — 모델 회사들의 인프라 분산 패턴다변화는 가격 결정권 게임의 협상력 도구이며, 이미 표준이다.본문으로 이동
- 카테고리별 글로벌 1등 — 종목 매핑카테고리별 1등은 베타가 다르다. 메모리는 한국이 글로벌 1등인 거의 유일한 영역이다.본문으로 이동
- 결론 — 큰 그림으로 다시큰 그림은 단순하다. 두 갈래 인프라가 동시에 폭증하고, 카테고리별 1등이 베타를 결정한다.본문으로 이동
Part 1 — 한 종류였던 것이 둘로 쪼개진다
AI 데이터센터를 한 덩어리로 보면 지금 일어나는 변화가 보이지 않는다. 2023년만 해도 그렇게 봐도 무리가 없었다. 모델 회사들이 짓는 시설은 주로 훈련용이었고, 추론은 그 옆에 끼워 두는 작은 작업 정도였다. AI 인프라 = 메가 클러스터 = NVIDIA + HBM + InfiniBand. 이 하나의 그림으로 거의 모든 게 설명됐다.
지금은 다르다. AI 데이터센터는 두 종류로 분리됐고, 그 분리가 점점 더 깊어지고 있다. 하나는 훈련용 — 외딴 곳에 자리한 거대 캠퍼스. 다른 하나는 추론용 — 도시 근처에 분산된 시설. 둘은 위치가 다르고 부품이 다르고 네트워크가 다르고 전력이 다르다. 같은 회사가 같은 모델을 위해 두 종류 시설을 따로 짓는다. 이게 이제 표준이다.
이 분리를 이해하지 못하면 AI 인프라 투자 지도가 흐려진다. 반대로 이해하면 향후 5년 자본이 어디로 흘러갈지 또렷하게 보인다.
먼저 가장 큰 변화부터 짚어야 한다. 추론이 훈련을 추월했다. 2023년 AI 컴퓨트의 3분의 2는 훈련에 쓰였고 추론은 3분의 1이었다. 2026년 초 이 비율이 뒤집혔다. 추론 워크로드가 AI 최적화 인프라 지출의 55%를 넘어섰고, 처음으로 훈련 비용을 추월했다. 2030년에는 더 벌어진다. McKinsey는 추론이 2030년 AI 컴퓨트의 70~80%를 차지할 것으로 본다. Lenovo CEO는 더 단호하게 말한다. "미래에는 80%가 추론, 20%가 훈련이 될 것"이라는 발언이다.
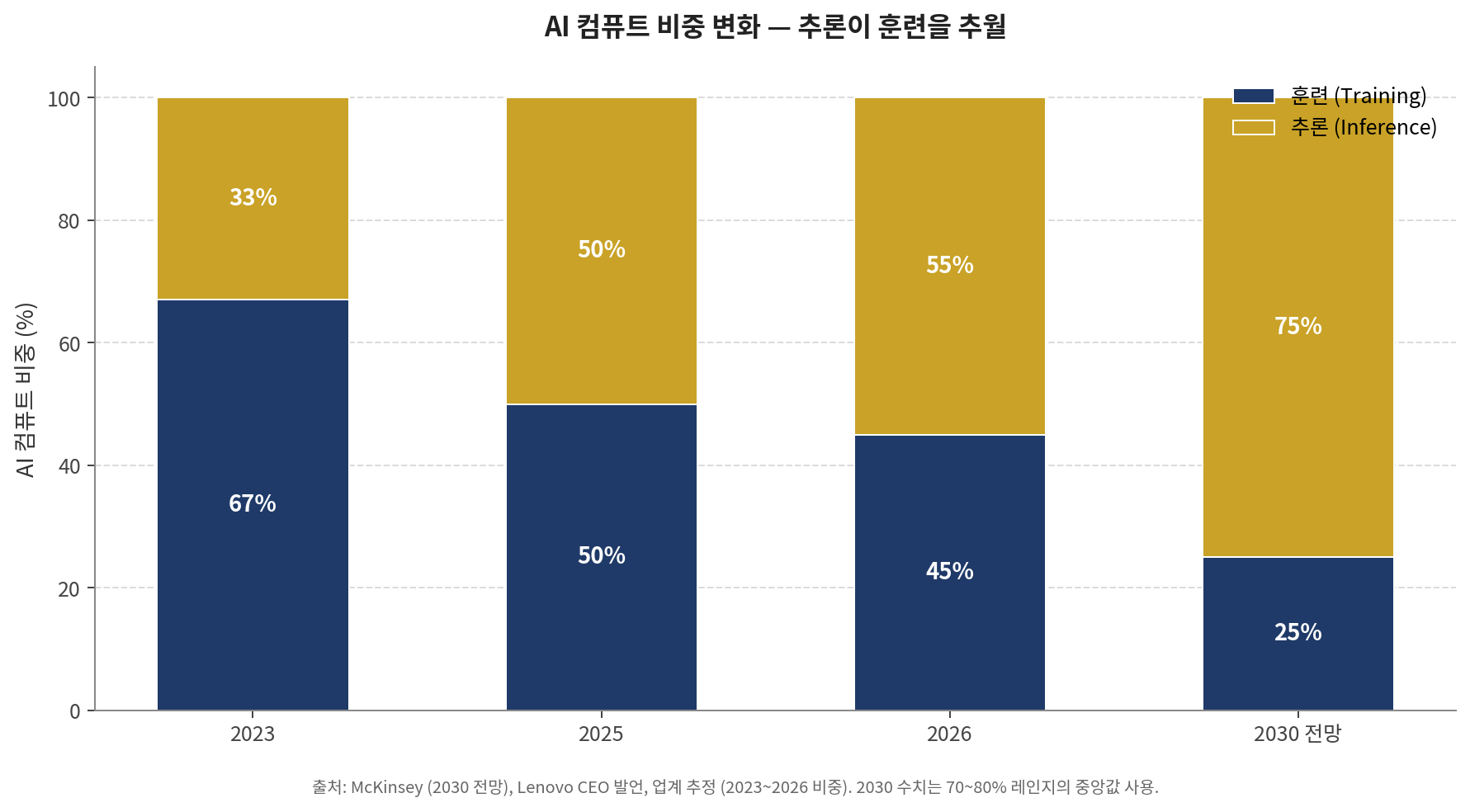
[그래프 1] AI 컴퓨트 비중 변화 — 추론이 훈련을 추월
이 숫자가 의미하는 바는 단순하다. AI 인프라 투자에서 "훈련 = 메인, 추론 = 부수적"이라는 통념은 끝났다. 이제 추론이 본진이다. 그리고 추론은 훈련과 완전히 다른 인프라를 요구하기 때문에, 이 비중 역전이 곧 데이터센터 자체의 분기로 이어진다.
분기의 첫 축은 위치다. 훈련용 데이터센터는 외딴 곳에 있어도 된다. 사용자가 즉각 응답을 받는 게 아니기 때문이다. 모델은 한 번 학습되면 그걸로 끝이고, 그 학습은 며칠에서 몇 달이 걸린다. 그래서 훈련 캠퍼스는 전기가 싸고 땅이 넓은 곳으로 간다. 텍사스 애빌린, 노스다코타 엘렌데일, 아이오와 같은 곳들이다. 추론은 정반대다. 사용자가 채팅창에 질문을 던지고 50ms 안에 답이 와야 한다. 소비자용 AI는 일반적으로 50ms 이하 응답 시간을 목표로 하며, 이는 추론 인프라가 인구 밀집 지역 근처에 있어야 한다는 뜻이다. 그래서 추론 시설은 도시 근처로 간다. 서울, 도쿄, 뉴욕, 런던 인근. 같은 회사가 한쪽에는 외딴 메가 캠퍼스를, 다른 한쪽에는 도시 근처 분산 시설을 동시에 운영한다.
위치가 다르면 전력 밀도도 달라진다. 훈련 시설은 전력 괴물이다. NVIDIA의 최신 GB200 GPU 랙 하나가 120kW를 먹는다. 일반 사무실 빌딩 수십 층 분량이다. 한 캠퍼스 전체로는 1GW를 넘는다. 원전 한 기 분량이다. 이 정도 전력 밀도에서는 공기로 식힐 수 없어서 액체 냉각이 필수가 된다. 칩에 직접 액체를 흘리거나 통째로 액체에 담그는 방식이다. 추론 시설은 다르다. 추론용 GPU는 카드당 600W 수준이고 랙당 10~40kW면 충분하다. 일반 데이터센터처럼 공랭 + 보조 냉각으로 돌아간다. 한 시설에 둘 다 넣으면 비효율이다. 액체 냉각 인프라를 추론 노드에 적용하는 건 자본 낭비고, 반대로 표준 시설에 훈련 클러스터를 넣으면 냉각이 부족하다. 그래서 분리는 단순한 선택이 아니라 물리적으로 강제된다.
가장 깊은 차이는 네트워크에서 나온다. 업계는 이미 두 네트워크를 분리해서 부른다. 백엔드 패브릭은 훈련용, 프런트엔드 네트워크는 추론용이다. 백엔드는 GPU끼리 빛의 속도로 대화하는 망이다. 훈련에서는 수천에서 수만 개 GPU가 동시에 같은 모델을 학습하는데, 매 단계마다 GPU들이 결과를 서로 교환해야 한다. 한 GPU가 늦으면 전체가 멈춘다. 그래서 극단적으로 빠르고 비싼 망이 깔린다. 서버 안에서는 NVLink가 GPU 8개를 묶는데, 대역폭이 1.8TB/s에 달한다. 일반 인터넷 회선의 수만 배다. 서버 사이는 InfiniBand 또는 고급 이더넷이 잇는다. 400G와 800G가 표준이다. 처리 시간의 30~50%가 네트워크에서 데이터 교환에 소비되며, AI 클러스터에서 네트워크 성능의 경제적 영향은 막대하다는 게 업계 합의다. 그래서 백엔드 네트워크는 클러스터 전체 비용의 20%까지 차지한다. 비싸도 안 깔면 GPU가 놀게 된다.
프런트엔드는 정반대다. 사용자 A의 질문과 사용자 B의 질문은 서로 무관하므로 GPU끼리 동기화될 필요가 없다. 훈련은 800G 이상 인터커넥트를 요구하지만 추론은 일반 이더넷에서 돌아간다. 알리바바가 이미 이렇게 운영한다 — 훈련 클러스터에는 InfiniBand를 쓰고 추론 클러스터에는 비용 효율적 확장을 위해 이더넷을 배치한다. 이 분리는 시장 자체를 둘로 가른다. 백엔드의 InfiniBand 진영은 NVIDIA가 Mellanox 인수로 거의 장악했다. 프런트엔드의 이더넷 진영은 Arista와 Broadcom이 주도한다. 추론 시장이 폭증한다는 건 이더넷 진영의 시장이 폭증한다는 뜻이다.

[그래프 2] 백엔드 패브릭과 프런트엔드 네트워크 — 같은 건물, 다른 시장
부품 구성으로 들어가면 더 흥미로운 그림이 나온다. 추론 시장이 곧 GPU 시장이라고 생각하기 쉽지만, 추론 서버 한 대를 뜯어보면 GPU 비중이 약 65% 정도다. 절대적이긴 해도 전부는 아니다. 나머지 35%는 무시할 수 없고, 그 부분이 추론 시장 폭증의 진짜 동반 수혜를 만든다. DDR5 시스템 메모리가 약 8%를 차지한다. NVIDIA는 GPU VRAM 총량의 최소 2배에 해당하는 CPU 시스템 메모리를 권장한다. 8-GPU 추론 서버 한 대에 DDR5가 1~2TB 들어간다는 뜻이다. NVMe SSD가 약 4%다. KV 캐시 백업과 모델 저장용으로 서버당 10~30TB. 이더넷 NIC가 약 5%로 400G 카드 8~9개. CPU와 메인보드, 전원, 섀시가 약 18%. 다 합치면 GPU 외 부품이 35%로 결코 작지 않은 비중이다.
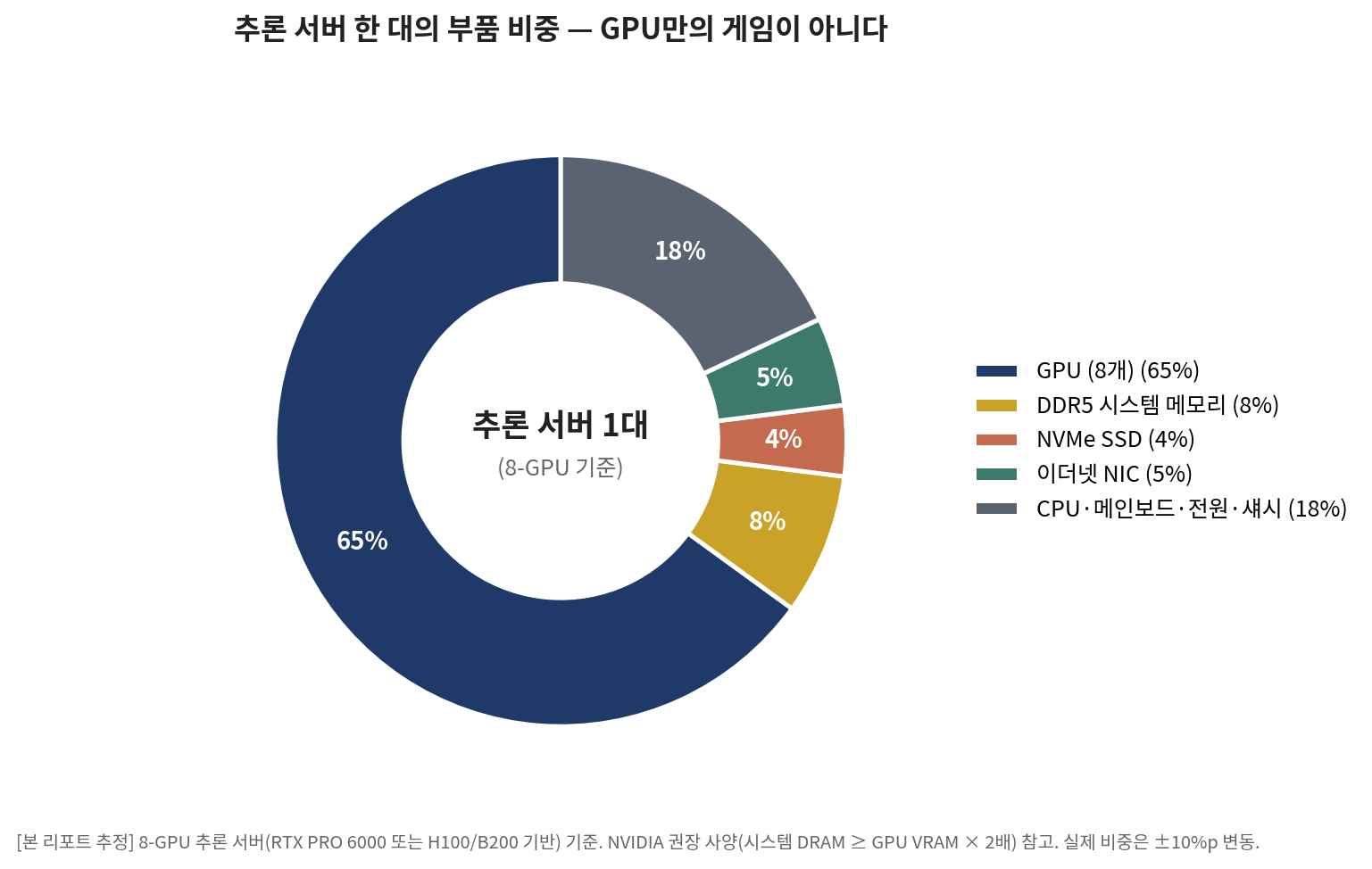
[그래프 3] 추론 서버 한 대의 부품 비중 — GPU만의 게임이 아니다
이 구조가 의미하는 바는 명확하다. 추론 시장 폭증은 GPU만의 게임이 아니다. GPU 매출이 1달러 늘 때, DDR5와 NVMe와 이더넷 NIC가 약 0.4~0.5달러 동반 성장한다. 메모리 3사인 SK하이닉스·삼성전자·Micron, NVMe 제조사, 이더넷 스위치 회사들이 모두 직접 수혜를 받는다. NVIDIA만 보고 있으면 이 동반 성장 구조가 보이지 않는다.
여기서 추론 분석의 진짜 깊은 곳으로 들어가야 한다. 많은 사람이 놓치는 부분인데, 추론 자체가 또 두 단계로 갈라진다. Prefill과 Decode다. Prefill은 사용자가 보낸 질문 전체를 모델이 한 번에 읽고 처리하는 단계로, 연산량이 폭발적이다. 짧고 강하게 GPU를 점유한다. 그래서 NVIDIA H100이나 B200 같은 고성능 GPU가 적합하다. Decode는 모델이 한 글자씩 답을 생성하는 단계로, 매번 모델 전체를 메모리에서 읽어와야 한다. 메모리 대역폭이 병목이고 연산은 거의 노는 상태로 길게 GPU를 점유한다. 이 단계는 RTX PRO 6000처럼 메모리는 빠르지만 가격이 훨씬 저렴한 칩으로 충분하다.
기존에는 같은 GPU가 두 단계를 다 처리했는데, 이게 비효율을 낳았다. 단계의 컴퓨트 부하가 decode 단계를 지연시키고, decode의 메모리 풋프린트는 동시 처리 가능한 prefill 작업 수를 제한한다. 해법은 두 단계를 다른 GPU에 분리하는 것이다. Prefill은 H100, Decode는 RTX PRO 6000. Meta·OpenAI·앤스로픽이 모두 이 구조를 채택하고 있고, Inference라는 이름으로 표준이 되어 가는 중이다. 이게 시사하는 바는 단순하다. 추론 시설 안에 두 종류의 GPU 풀이 들어간다는 것은 NVIDIA 단독 시장이 아니라는 뜻이다. AMD, Cerebras, Broadcom 커스텀 ASIC이 들어올 자리가 명확히 생긴다. NVIDIA의 추론 시장 독점이 깨지는 기술적 근거가 여기 있다.
마지막으로 가장 흔한 오해를 정리해야 한다. "추론 비중이 커진다 = 훈련은 끝났다"는 통념이다. 이건 틀렸다. 비중과 절대량은 다르다. 훈련 비중이 33%에서 20%로 떨어지더라도 시장 자체가 5배에서 10배로 커지면 훈련 절대량은 오히려 증가한다. 수치가 그걸 보여준다. 프런티어 훈련 전력 수요는 연 2.2~2.9배 성장하며, 단일 훈련 런이 2030년까지 4~16GW에 도달할 수 있다. 현재 가장 큰 단일 시설인 앤스로픽-AWS New Carlisle은 1.1GW 350억 달러 규모인데, Microsoft Fairwater Wisconsin은 2027년 9월까지 거의 8배 더 커진다.
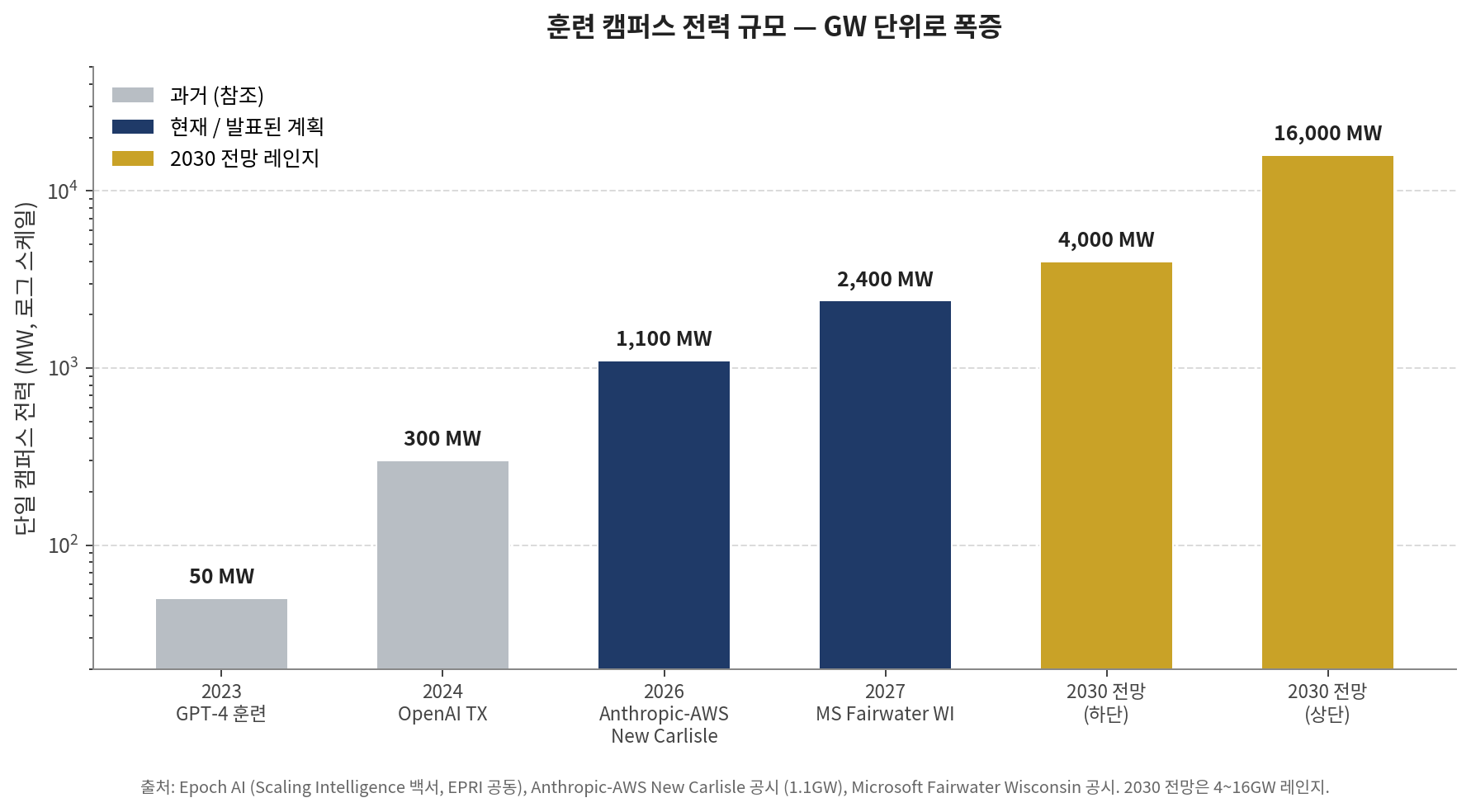
[그래프 4] 훈련 캠퍼스 전력 규모 — GW 단위로 폭증
훈련은 줄지 않는다. GW 단위로 폭증한다. 게다가 훈련의 형태 자체가 확장되고 있다. 사전훈련만 보면 줄어들 수 있지만, 사후훈련과 강화학습, 합성 데이터 생성이 모두 추가된다. o1과 R1 같은 reasoning 모델은 RL 단계에 사전훈련만큼 큰 컴퓨트를 쏟아붓는다. 이 모든 게 백엔드 시설에서 일어난다. 그래서 훈련 시장과 추론 시장은 둘 다 동시에 폭증한다. 한쪽이 다른 쪽을 죽이는 게임이 아니라 보완 관계다. 추론으로 돈을 더 벌수록 더 좋은 모델을 만들 ROI가 명확해지고, 그게 더 큰 훈련 클러스터 투자로 이어진다.
여기까지가 Part 1의 진단이다. AI 데이터센터는 두 종류로 분리됐고, 둘 다 동시에 폭증한다. 진짜 그림을 보려면 두 갈래를 따로 봐야 한다. 훈련 갈래에서 던질 질문은 셋이다. GW급 캠퍼스를 누가 짓느냐. 그 전력은 어디서 오느냐. 그 사이를 잇는 광 백본은 누가 까느냐. 추론 갈래의 질문도 셋이다. 어디에 분산되느냐. 표준 부품을 누가 공급하느냐. 누가 새로운 클라우드 카테고리를 차지하느냐. Part 2와 Part 3에서 이 질문들에 답한다.
훈련은 줄지 않는다. 추론과 훈련은 둘 다 동시에 폭증하는 보완 관계다.